
Temps de lecture : 21 minutes
Dans cet article, nous allons voir comment créer de A à Z un projet de Data engineering : un data pipeline ETL, la création de notre schéma de données, l’ORM de l’application, son backend et ensuite son déploiement avec Streamlit Cloud.
L’objectif est de récupérer la liste des prix de stations essence en France, d’automatiser un job qui va venir mettre à jour les valeurs quotidiennement, pour ensuite construire un dashboard qui affichera les prix personnalisés aux utilisateurs du site.
Après la lecture de ce billet de blog, vous aurez les bases pour construire des dashboards data, et pour scrapper vos propres sources de données pour les exposer.
Et si vous êtes un simple lecteur sans velléité de dev ? Vous pourrez économiser à la pompe avec le dashboard, et réinvestir le reste pour la transition écologique.
C’est parti !
Un data pipeline pour connaître les prix à la pompe près de chez soi
Je ne prends pas souvent ma voiture (l’avantage du réseau francilien de transports en commun), mais quand je dois le faire, il me vient toujours un grand dilemme. Avec la multiplicité des stations essences autour de chez moi, et la volatilité des prix à la pompe ces derniers temps, comment choisir systématiquement la moins chère ?
En France nous avons l’opportunité de disposer d’APIs publiques maintenues par des services gouvernementaux. Malheureusement, le site web ne fait qu’exposer les prix et ne permet pas de sauvegarder ses stations préférées. Il faut donc lister les prix de chaque station sur le site, qui n’est pas vraiment optimisé pour les mobiles en plus.
Il y a quelques années, après avoir dockerizé 2 / 3 choses sur ma Raspberry PI à la maison, et m’être fait un peu la main sur Flask, j’avais exposé un site très très minimal qui affichait les prix. Le backend était un peu sale (tout était hardcodé), mais efficace. Par contre, aucun moyen de faire évoluer l’app…
Quand je montrais l’application à mes proches et mes amis, réaction systématique de leur part : “Trop bien, je peux mettre mes stations à moi ?” Et moi de leur répondre, “Ah, euh non désolé, je ne peux mettre que les miennes pour l’instant”. Et ce n’était pas par manque de volonté, mais littéralement le code était trop monolithique pour faire évoluer quoi que ce soit, à mon grand désarroi.
L’idée a donc germé, mon nouvel objectif de projet était très clair : créer un dashboard exposé sur le web, en open source, avec uniquement du free-tier. Ce dashboard devait pouvoir être accessible par n’importe qui, et on devait pouvoir y créer son compte, gérer ses listes de stations et surtout faire des économies sur le carburant.
D’ailleurs, l’énergie la moins chère reste toujours celle qu’on ne consomme pas. Prenez votre vélo ou votre paire de jambes dès que possible, c’est bon pour votre corps, votre porte-monnaie, votre esprit et pour la planète !
La version live est dispo ici 🚀
Pour commencer, comme dans tout projet de Data Engineering et de BI, la pierre angulaire du travail à effectuer réside dans nos données. La donnée doit être disponible, et de qualité. Travaillons en premier sur cet aspect.
Pour scrapper et récupérer notre donnée, i.e. les prix à la pompe, nous utiliserons la nouvelle plateforme d’Open Data mise en oeuvre pas les services gouvernementaux français. Un flux quotidien y est maintenu, et de relativement bonne qualité.
Le format est relativement simple, il ne s’agit pas d’une API Rest comme rencontré classiquement, mais d’un fichier XML exposé sur une URL. Toutes les données de prix, de localisation et de dates de mises à jour y sont contenues.
Voici ci-dessous un extrait du fichier afin d’illustrer le format de donnée :
<?xml version="1.0" encoding="ISO-8859-1" standalone="yes"?>
<pdv_liste>
<pdv id="91190012" latitude="4870300" longitude="212800" cp="91190" pop="R">
<adresse>27 AV DU GENERAL LECLERC</adresse>
<ville>Gif-sur-Yvette</ville>
<horaires automate-24-24="1">
<jour id="1" nom="Lundi" ferme="1"/>
<jour id="2" nom="Mardi" ferme="1"/>
<jour id="3" nom="Mercredi" ferme="1"/>
<jour id="4" nom="Jeudi" ferme="1"/>
<jour id="5" nom="Vendredi" ferme="1"/>
<jour id="6" nom="Samedi" ferme="1"/>
<jour id="7" nom="Dimanche" ferme="1"/>
</horaires>
<services>
<service>Station de gonflage</service>
<service>Carburant additiv<E9></service>
<service>Automate CB 24/24</service>
</services>
<prix nom="Gazole" id="1" maj="2024-05-08 12:30:00" valeur="1.739"/>
<prix nom="SP98" id="6" maj="2024-05-11 13:15:00" valeur="1.999"/>
<rupture nom="E10" id="5" debut="2024-05-10 16:16:02" fin="" type="temporaire"/>
</pdv>
</pdv_liste>La première bonne nouvelle pour tout Data Eng aguerri, c’est la manière de représenter les données des stations ! Elles sont toutes listées par un objet XML bien défini, pdv (l’acronyme de point de vente), qui se paie le luxe d’avoir un identifiant unique. Un bon présage pour la réconciliation de donnée à chaque update, même si rien ne présume quant à une stabilité espérée du schéma de donnée.
C’est d’ailleurs le côté négatif de la représentation par fichier. Avec une API et une version, les Standard OpenAPI permettent de facilement voir les évolutions. Ici ce sera quand le script hurlera des erreurs dans tous les sens (au mieux) que nous verrons les incompatibilités.
Deuxième point rassurant, la latitude et la longitude des stations sont fournies ! C’est parfait afin de pouvoir représenter les stations sur une carte. Pas besoin de s’embêter avec du Géo-encodage, ou de la réconciliation d’adresse. J’ai toujours trouvé les cartes plus intuitives dans ces cas-là.
Enfin, nous retrouvons l’objet principal de nos recherches dans le champ prix :
- Une liste de prix pour les types de carburants fournis par la station, ainsi que la date de dernière mise à jour.
- Également la liste des services proposés par la station (lavage, automate 24/24). À noter, mais à priori nous ne nous en servirons pas dans le projet. Laissons ça pour un autre développeur qui pourra développer Find My CarWash.
Construisons désormais des entités et des associations entre elles, sur la base de ce que nous avons pu trouver dans ce fichier de données. Nous y ajouterons les informations contextuelles dont nous avons besoin dans le cadre du projet : des utilisateurs par exemple.
Gestion de la base d’utilisateurs
Pour gérer les utilisateurs, la création de comptes avec mots de passe, d’emails, nous définirons une table très simple. Elle contiendra uniquement les emails, noms et pseudos des utilisateurs. Tous les détails de chiffrement, de token d’authentification JWT seront managés par une libraire externe au référentiel de donnée de l’application : Streamlit-Authenticator.
L’idée est simplement de refléter les utilisateurs référencés par cette librairie, et d’ajouter ceux-ci à la table mentionnée précédemment. Pour éviter de manipuler en base des éléments sensibles comme des mots de passe, même chiffrés avec un système conventionnel de hash et de salt, aucune association ne sera faite dans la base de donnée. Appliquons l’idée de least privilege, et ici rien n’indique le besoin d’avoir l’accès aux mots de passe.
Malheureusement, dans la manière d’utiliser cette librairie, le fonctionnement classique expose chaque utilisateur à un risque de sécurité. En effet, en cas d’oubli de mot de passe, la seule option proposée consiste à réinitialiser le mot de passe. Donc n’importe qui pourrait demander la ré-initialisation de celui-ci, sans l’aval de l’utilisateur concerné..
Afin de contourner ce risque, l’idée est d’envoyer par mail un code vérification à l’utilisateur. Si ce code correspond à ce qui a été envoyé, alors il peut recevoir un nouveau mot de passe par le biais de cette adresse mail.
Le stockage de cette logique applicative sera effectué dans une table dédiée, contenant les dates de génération (afin de gérer l’expiration), ainsi que les codes de vérification envoyés.
Gérer les stations essences recensées et les prix
Pour permettre aux utilisateurs de créer une liste de stations essence personnalisée, une table Custom_station sera dérivée de la Stations. Chaque instance de l’objet Price sera associée à une station. Et un prix aura évidemment son association avec un type de carburant. C’est-à-dire qu’il pourra être défini comme un diesel, un essence SP95, E10, E85, GPL, etc.
Pour que les utilisateurs puissent choisir quels types de carburant les intéressent, une table d’association doit être déclarée. Elle marque le lien au niveau de l’ORM SQLAlchemy entre un utilisateur et un type de carburant, de la table gas_types.
Ci-dessous, un diagramme avec toutes les entités et les associations permet de résumer les objets de notre modèle de donnée. Les types d’association (1:1 / Many to One) ne sont pas représentés, mais l’ajout des clés primaires et étrangères est indiqué. Cela devrait être suffisant pour lire le diagramme et comprendre les principales relations.
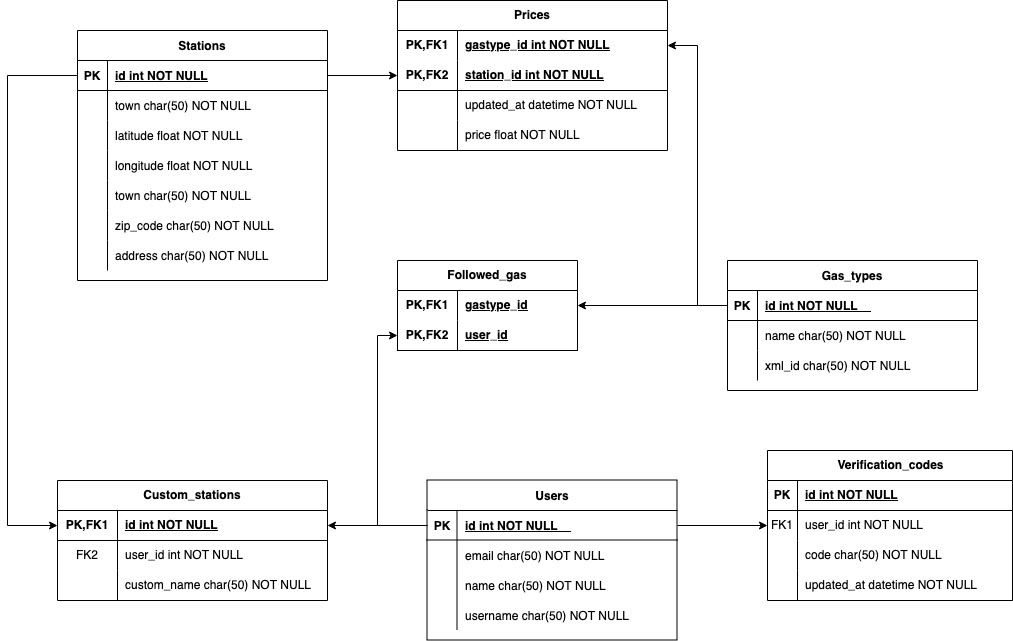
Déclarer ces entités dans un ORM
Afin d’utiliser facilement toutes ces tables, nous allons déclarer les classes SQLAlchemy et les relier entre elles. Pour cela, nous utiliserons la version 2 de cette librairie Python, avec l’implémentation déclarative.
Voici la déclaration de ces différentes classes, sous le module models.py de notre application
from typing import List
import sqlalchemy as sa
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column, relationship
class Base(DeclarativeBase):
pass
association_table = sa.Table(
"association_table",
Base.metadata,
sa.Column("gastype_id", sa.ForeignKey("gas_types.id"), primary_key=True),
sa.Column("user_id", sa.ForeignKey("users.id"), primary_key=True),
)
class GasType(Base):
__tablename__ = "gas_types"
# id = sa.Column(sa.Integer, primary_key=True)
id: Mapped[int] = mapped_column(primary_key=True)
xml_id = sa.Column(sa.String, nullable=False)
name = sa.Column(sa.String, nullable=False)
users: Mapped[List["User"]] = relationship(
secondary=association_table, back_populates="gastypes"
)
def __repr__(self):
return f"<GasType {self.name}>"
class User(Base):
__tablename__ = "users"
# id = sa.Column(sa.Integer, primary_key=True)
id: Mapped[int] = mapped_column(primary_key=True)
email = sa.Column(sa.String, unique=True, nullable=False)
username = sa.Column(sa.String, unique=True, nullable=False)
name = sa.Column(sa.String, nullable=False)
# add a reference to the stations
stations = relationship("CustomStation")
# add a reference to the gas types followed
gastypes: Mapped[List["GasType"]] = relationship(
secondary=association_table, back_populates="users"
)
def __repr__(self):
return f"<User {self.username}>"
def to_dict(self):
return {
"id": self.id,
"email": self.email,
"username": self.username,
"name": self.name,
}
def to_csv(self):
return f"{self.id},{self.email},{self.username},{self.name}"
class VerificationCode(Base):
__tablename__ = "verification_codes"
id = sa.Column(sa.Integer, primary_key=True)
user_id = sa.Column(sa.Integer, sa.ForeignKey("users.id"), nullable=False)
code = sa.Column(sa.String, nullable=False)
created_at = sa.Column(sa.DateTime, nullable=False)
def __repr__(self):
return f"<VerificationCode {self.id}>"
class Station(Base):
__tablename__ = "stations"
id = sa.Column(sa.Integer, primary_key=True)
latitude = sa.Column(sa.Float, nullable=False)
longitude = sa.Column(sa.Float, nullable=False)
town = sa.Column(sa.String, nullable=False)
address = sa.Column(sa.String, nullable=False)
zip_code = sa.Column(sa.String, nullable=False)
sa.Index("latitude_longitude_index", latitude, longitude, unique=True)
def __repr__(self):
return f"<Station {self.id}>"
def to_dict(self):
return {
"id": self.id,
"latitude": self.latitude,
"longitude": self.longitude,
"town": self.town,
"address": self.address,
"zip_code": self.zip_code,
}
class CustomStation(Base):
__tablename__ = "custom_stations"
id = sa.Column(sa.Integer, sa.ForeignKey("stations.id"), primary_key=True)
user_id = sa.Column(sa.Integer, sa.ForeignKey("users.id"), nullable=False)
custom_name = sa.Column(sa.String, nullable=False)
def __repr__(self):
return f"<CustomStation {self.id}-{self.user_id}>"
def to_dict(self):
return {
"id": self.id,
"user_id": self.user_id,
"custom_name": self.custom_name,
}
class Price(Base):
__tablename__ = "prices"
gastype_id = sa.Column(sa.Integer, sa.ForeignKey("gas_types.id"), primary_key=True)
station_id = sa.Column(sa.Integer, sa.ForeignKey("stations.id"), primary_key=True)
updated_at = sa.Column(sa.DateTime, nullable=False)
price = sa.Column(sa.Float, nullable=False)Bien ! Et comment utiliser ces différentes classes dans notre application Streamlit ?
Rien de bien compliqué, il nous suffit d’instancier un objet de type Session !
Voici comment déclarer cela sous le module session.py :
import logging
from functools import lru_cache
from typing import Generator
import sqlalchemy
import streamlit as st
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session, sessionmaker
from sqlalchemy_utils import create_database, database_exists
from models import Base, GasType
logger = logging.getLogger("gas_station_app")
engine = create_engine("sqlite:///db.sqlite3", pool_pre_ping=True)
@lru_cache
def create_session() -> scoped_session:
"""Create a session given the url in settings."""
Session = scoped_session(
sessionmaker(autocommit=False, autoflush=False, bind=engine)
)
return Session
def get_session() -> Generator[scoped_session, None, None]:
"""Retrieve a session."""
Session = create_session()
try:
yield Session
finally:
Session.remove()
database_creation = False
db_session = create_session()
logger.info("session created")
created_engine = db_session.bind
if not database_exists(created_engine.url):
logger.info("Database does not exist, creating it")
create_database(created_engine.url)
database_creation = True
Base.metadata.bind = engine
Base.metadata.create_all(bind=created_engine)
### initialize the database with mandatory data
def create_gastypes(db_session):
"""
Create the gas types in the database.
Args:
db_session: sqlalchemy session
Returns:
None
"""
logger.info("Creating gas types")
gas_dict = {"Gazole": 1, "SP95": 2, "SP98": 6, "E85": 3, "GPLc": 4, "E10": 5}
for name, xml_id in gas_dict.items():
if not db_session.query(GasType).filter(GasType.name == name).first():
gas_type = GasType(name=name, xml_id=xml_id)
db_session.add(gas_type)
try:
db_session.commit()
except sqlalchemy.exc.IntegrityError:
db_session.rollback()
if database_creation:
create_gastypes(db_session=db_session)
Ces différentes lignes peuvent paraître complexes, mais si on les relit séquentiellement, c’est très simple à comprendre. Au démarrage de l’application, le module est initialisé par Python (puisqu’il est importé par home.py, le main de notre application).
Une instanciation de session est donc effectuée : engine = create_engine("sqlite:///db.sqlite3", pool_pre_ping=True) va venir créer le moteur de l’ORM sqlalchemy.
Comme nous allons utiliser un cache LRU, les appels seront moins fréquents à la base SQLite, les objets en cache seront réutilisés par les différents appels de l’application. Python réutilisera le même objet de sortie de la fonction get_session plusieurs fois, jusqu’à expiration du cache.
Désormais, intéressons-nous à cette étrange fonction create_gastypes. Que fait-elle ?
Si SQLAlchemy détecte que la base SQLite est vide, sans les tables du schéma, alors le moteur ORM va déclencher la création de ces tables et du schéma associé dans le module models.py. Pour fonctionner correctement, notre table gas_types doit être alimentée avec la donnée du référentiel de l’API Open Data.
Ici aucun moyen de récupérer ces identifiants de manière automatique, il va falloir coder ces valeurs en dur, et prier pour que cela n’évolue pas sans prévenir dans le temps..
Et c’est tout ! Tous les autres modules pourront effectuer des appels à l’objet db_session de ce module, et le tour est joué.
Notre DataWarehouse/Entrepôt de donnée est prêt à recevoir la donnée de notre ETL, penchons-nous maintenant sur ce bloc d’architecture.
NB: ici je ne couvrirais pas les éléments de Streamlit-Authenticator, ceux-ci sont très bien illustrés dans la documentation GH du package, allez y jeter un oeil !
Rafraîchissement quotidien de la donnée
Résumons ce dont nous disposons désormais :
- Un workspace Streamlit gratuit, qui peut récupérer quotidiennement de la donnée et déposer les valeurs dans une DB SQLite
- Un fichier d’export exposé depuis une API Open Data publique
- Une UI à l’adresse carburoam.streamlit.app qui ne peut qu’exposer l’application Streamlit (il faut malheureusement abandonner l’idée de pouvoir y brancher un
airflow,dagsteret compagnie..)
Donc où est caché notre ETL ici ? En effet, il nous manque une pièce centrale dans notre projet de Data Engineering : l’outil d’orchestration des flux de traitements de donnée !
Si nous pouvions avoir une instance d’airflow quelque part, alors assurément nous pourrions répondre à ce problème avec ce genre d’outillage, mais il faut faire une croix dessus ici..
Construisons alors quelque chose de plus simple. Ce ne sera pas très résilient, mais à l’échelle du projet, considérons que ce sera amplement suffisant.
Orchestrateur de jobs en pur Python
Pour déclencher nos jobs, nous allons uniquement nous baser sur le process Python principal, et créer un child-process, afin de déclencher tout le mécanisme d’update. Ce sous-process va contenir uniquement un Thread avec un timer, qui va déclencher quotidiennement une tâche afin de :
- Extraire le fichier depuis l’API Open Data
- Itérer sur les items exportés depuis le fichier pour les charger en base
Techniquement, on pourrait presque appeler ça un bébé “Hello World” de job CRON. Voyons comment créer pas à pas, cet élément :
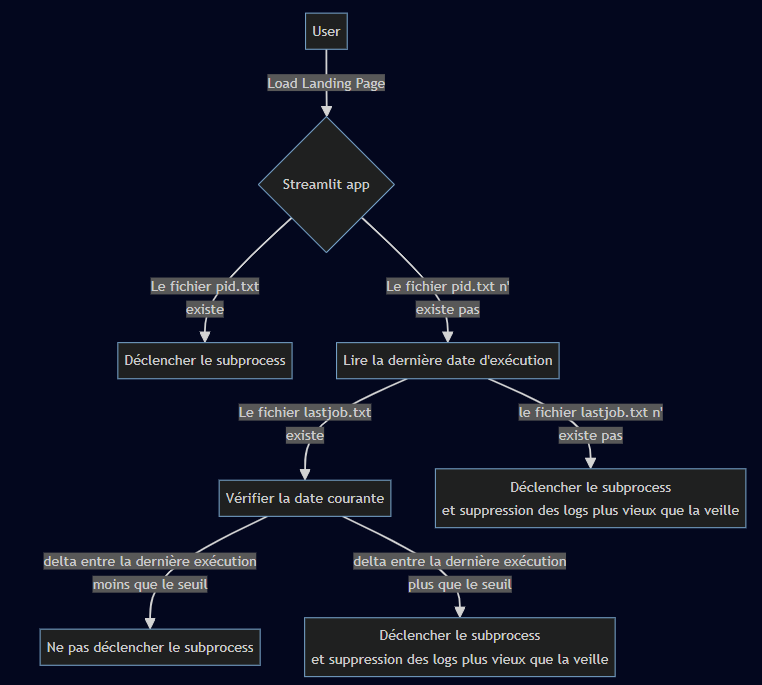
Est-ce que cela suffit ? À peu près, oui ! Nous aurions pu utiliser la base de données afin de stocker ces événements, cela aurait simplement demandé d’avoir un watcher Python qui viendrait requêter la table périodiquement. Pour éviter une surcharge de la DB, une simple gestion par fichier remplace les marqueurs de complétion. Nos 2 marqueurs se font avec :
pid.txt: contient le PID du job d’ETL avec le thread et son timerlastjob.txt: contient la date de dernière exécution
De cette façon, la base de donnée ne sera pas surchargée durant les développements. Un redéploiement du code source de l’application ne déclenchera pas de job d’ETL supplémentaire si la dernière date est récente.
Si un problème apparaît lors de l’ETL, nous pouvons tuer le subprocess via son PID et en démarrer un nouveau, en supprimant le fichier pid.txt.
Afin d’assurer un minimum de maintenabilité durant le debugging, les flux stdout et stderr du script seront redirigés vers un fichier text, sous le dossier outputs.
import logging
import os
import subprocess
import sys
import uuid
from datetime import datetime
from pathlib import Path
import streamlit as st
from utils import WAIT_TIME_SECONDS
logger = logging.getLogger("gas_station_app")
def trigger_etl():
"""
Trigger the ETL process in a subprocess.
"""
# create a new uuid for process opening
str_uuid = str(uuid.uuid4())
with open(f"outputs/stdout_{str_uuid}.txt", "wb") as out, open(
f"outputs/stderr_{str_uuid}.txt", "wb"
) as err:
subprocess.Popen([f"{sys.executable}", "utils.py"], stdout=out, stderr=err)
if not os.path.exists("pid.txt"):
logger.info("No pid file found, creating one")
# if it doesn't exist, trigger the subprocess job
# delete and remove output files under outputs
for file in Path("outputs").glob("*.txt"):
# get last modified date
try:
last_modified = datetime.fromtimestamp(file.stat().st_mtime)
# if the file is older than 1 day, remove it
if (datetime.now() - last_modified).days > 1:
logger.info(f"Removing {file}")
file.unlink()
except FileNotFoundError:
# it means another process has deleted the file
pass
if os.path.exists("lastjob.txt"):
# check the last job date, do not start subprocess if recent
with open("lastjob.txt", "r") as file:
date = file.read()
# parse the date (dumped as datetime.now())
date = datetime.strptime(date, "%Y-%m-%d %H:%M:%S.%f")
st.session_state["lastjob"] = date
# if the detla from now is greater than WAIT_TIME_SECONDS
if (datetime.now() - date).total_seconds() > WAIT_TIME_SECONDS:
logger.info("Last job was not recent, starting new job")
trigger_etl()
else:
logger.info("Last job was recent, skipping")
else:
trigger_etl()
if os.path.exists("lastjob.txt"):
with open("lastjob.txt", "r") as file:
date = file.read()
date = datetime.strptime(date, "%Y-%m-%d %H:%M:%S.%f")
st.session_state["lastjob"] = dateAvec la donnée de dernière exécution en cache, nous pouvons aussi avoir une bonne métrique affichant la date de dernier job d’extraction.

NB : L’élément sys.executable est très important pour s’assurer que l’exécutable Python utilisé est le même que celui utilisé par l’application Streamlit, celle de l’environnement virtuel où toutes les dépendances y sont installées. Utiliser directement python pourrait causer des bugs
Qu’en est-il de l’implémentation du thread avec timer ?
Plutôt simple aussi :
import os
import signal
from threading import Timer
import threading
WAIT_TIME_SECONDS = 60 * 60 * 6 # each 6 hours
class ProgramKilled(Exception):
pass
def signal_handler(signum, ffoorame):
raise ProgramKilled
class Job(threading.Thread):
def __init__(self, interval, execute, *args, **kwargs):
threading.Thread.__init__(self)
self.daemon = False
self.stopped = threading.Event()
self.interval = interval
self.execute = execute
self.args = args
self.kwargs = kwargs
def stop(self):
self.stopped.set()
self.join()
def run(self):
while not self.stopped.wait(self.interval.total_seconds()):
self.execute(*self.args, **self.kwargs)
def main_etl():
print("Running ETL job at ", datetime.now())
# print the process pid
print("Process ID: ", os.getpid())
with open("lastjob.txt", "w") as file:
file.write(str(datetime.now()))
loadXML()
dump_stations()
def etl_job():
# check if status file exists
if not os.path.exists("pid.txt"):
with open("pid.txt", "w") as file:
file.write(str(os.getpid()))
# start etl at beginning of the thread
main_etl()
signal.signal(signal.SIGTERM, signal_handler)
signal.signal(signal.SIGINT, signal_handler)
job = Timer(WAIT_TIME_SECONDS, main_etl)
job.start()
while True:
try:
time.sleep(1)
except ProgramKilled:
print("Program killed: running cleanup code")
# remove the pid file
if os.path.exists("pid.txt"):
os.remove("pid.txt")
job.cancel()
break
else:
print("PID file already found, job as already started. Exiting...")
exit(1)
if __name__ == "__main__":
etl_job()La routine principale est implémentée sous la fonction etl_job qui était précédemment importée. Ici, une double vérification est utilisée, pour vérifier que le fichier PID n’a pas déjà été créé (avec la concurrence, une multitude d’utilisateurs pourrait essayer de lancer la page d’accueil en même temps).
Les “signals handlers” permettent de faire un nettoyage des éléments (le pid.txt notamment) lorsque le signal SIGTERM est reçu du process parent. C’est à dire que dès que l’application est arrêtée, alors le thread lancera le nettoyage.
Ensuite, nous démarrons le timer et lançons une boucle infinie, jusqu’à qu’une Exception soit levée par le “signal handler”. De cette manière, le script supprime le fichier PID.
Parfait ! Nous avons désormais notre système d’ETL pour charger en base les différents prix exposés sur l’API gouvernementale.
Construisons un dashboard ergonomique, afin que les utilisateurs puissent :
- Consulter la page principale, avec une liste des prix triés par stations et valeurs, ainsi que la redirection vers les autres pages
- Se connecter au site web, recevoir leur mot de passe, nom d’utilisateur automatiquement s’ils l’ont oublié
- Modifier, Ajouter et Supprimer leur profil utilisateur, en leur donnant le contrôle total dessus (RGPD compliant) sur les champs utilisateurs (email, nom) et les types de carburants préférés.
- Choisir de nouvelles stations à ajouter/supprimer de leurs stations favorites
En bonus :
- Une page d’informations, pour montrer un guide d’utilisation
- Une barre de navigation verticale qui donne un style très professionnel, grâce à une base inspirée de cette app open source1, avec l’UI de la barre verticale.
Fabrication et design de l’UI
Page d’accueil
La page d’accueil doit se comporter différemment le statut de l’utilisateur, selon si l’utilisateur est connecté ou non. Sur la base de cette connaissance, l’UX doit être différente. Voyons étape par étape comment construire une UX cohérente.
Utilisateurs non loggés
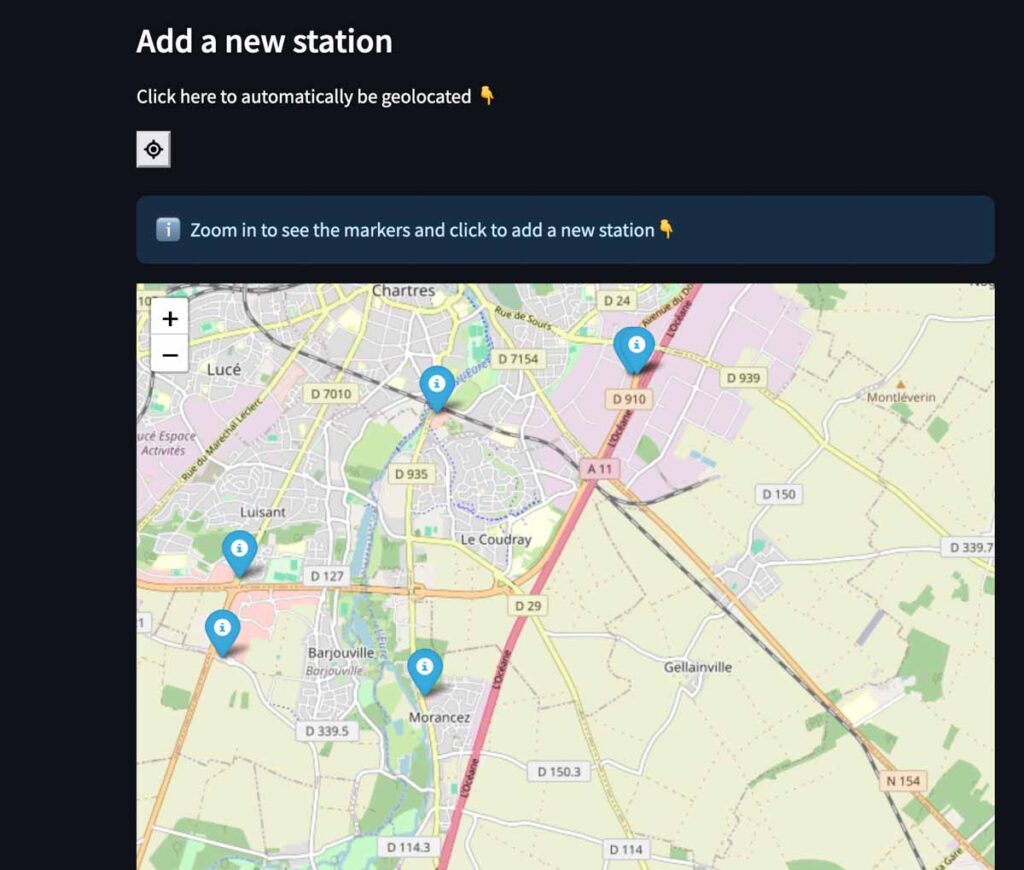
Pour les nouveaux arrivants, les idées principales sont :
- Fournir en première intention un moyen de créer un compte sur la plateforme
- Proposer une démo du dashboard. Personnellement, je ne me vois pas créer un compte sur quelque chose dont je ne peux pas voir la valeur ajoutée (achat, personnalisation ou autre valeur ajoutée par une app !). Ajouter une page démo me semble donc un vrai bonus, si ce n’est quasi-obligatoire !
- Enfin, montrer un page explicative à propos de l’application, et laisser l’utilisateur comprendre, explorer un peu les insights de l’application. Pour les développeurs, c’est aussi ici que le lien vers le repo Open Source est dispo !
Utilisateurs connectés
Pour les utilisateurs qui ont créé un compte et qui se sont connectés sur l’application, si je me mets à leur place, j’aimerais (par ordre de priorité) :
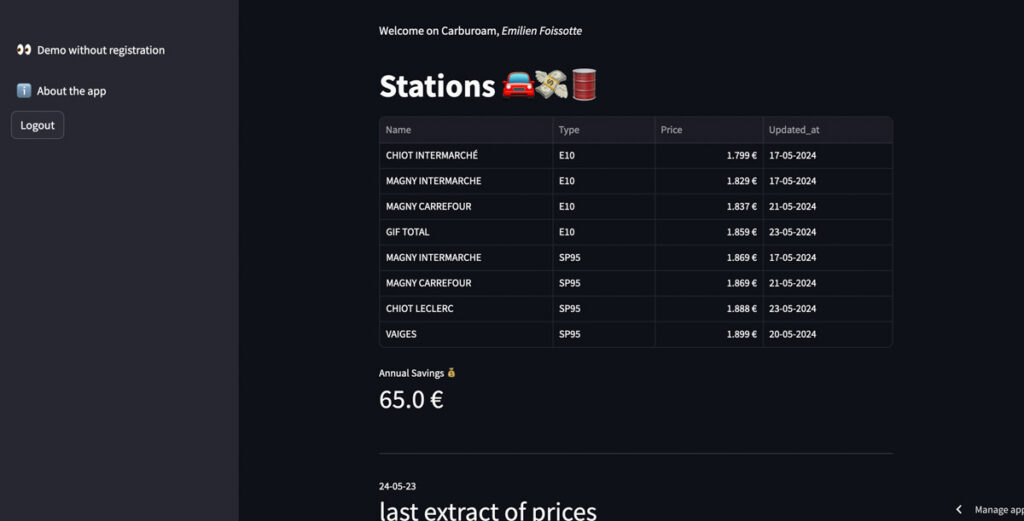
- Pouvoir rapidement repérer les prix de mes stations enregistrées, et identifier le prix le moins cher
- Être capable de savoir de quand date le rafraîchissement du prix pour chaque station, et de l’extract complet
- Evaluer les économies faites grâce à l’utilisation du dashboard, pour engager à l’utiliser (nudge)
- Voir rapidement ce que permet le dashboard en termes de customisation de profil, stations, etc.
Console d’administration
Pour les besoins d’administration, la console de l’application web doit pouvoir fournir :
- Quelques données à propos du traffic de l’app, son taux d’utilisation, d’adoption
- Des options de gestion d’opérations pour les utilisateurs, pour les besoins de support (réinitialisation de mot de passe, refresh des jobs ETL et monitoring des logs locaux, possibilité de lancer du code shell)
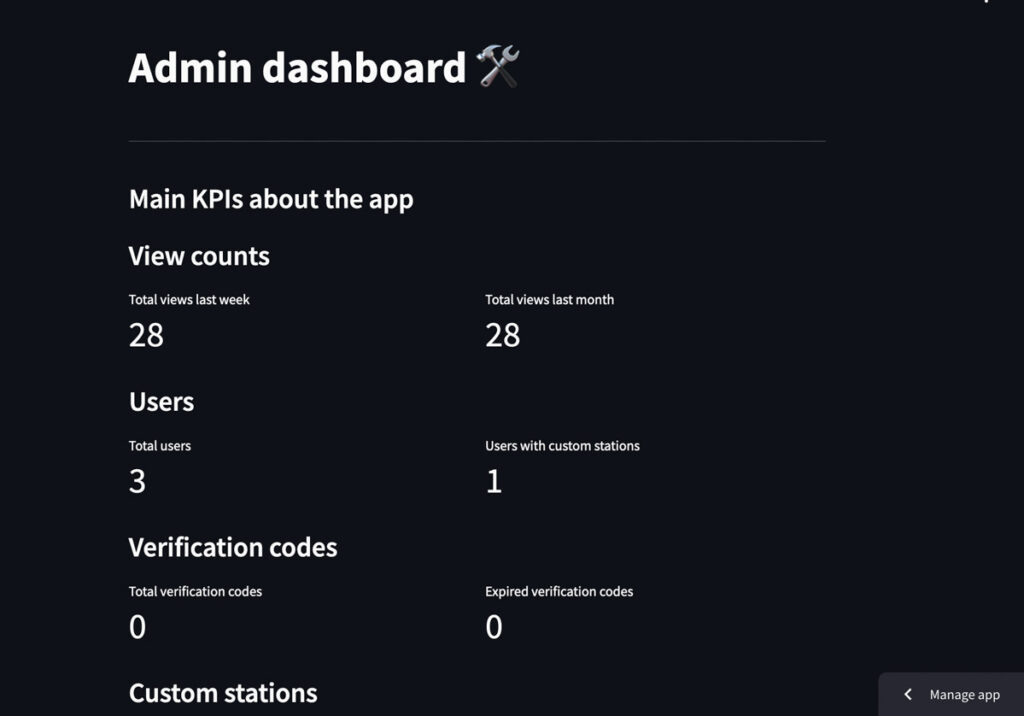
Grâce au système d’authentification, il est possible de restreindre l’accès à ce dashboard uniquement à l’utilisateur admin. Ainsi, aucune donnée sensible ne pourra être exfiltrée par un utilisateur malicieux.
En packageant toutes ces pages, les différents modules utilitaires pour les jobs d’ETL, et en déployant le code sur un repo Github, nous avons une application Streamlit en live sur le cloud. Tout est hébergé par Streamlit !
Garder l’application active et le fichier DB local dans la durée
Comme nous l’avons vu auparavant, la database SQLite va bootstrapper les différentes instances de Users sauvegardées dans le fichier d’authentification, sauvegardé sur le stockage AWS S3.
Par contre, les instances Stations, Price et CustomStation ne sont visibles que depuis la DB SQLite. Il y a donc un risque, si jamais nous perdons le fichier SQLite (en cas de reboot de l’environnement Streamlit par exemple, il est explicitement mentionné que Streamlit ne garantit pas la persistance des DB locales).
Pour éviter que l’application tombe en mode veille et que l’orchestrateur de Streamlit décommissionne intempestivement le conteneur, la VM ou le serveur où tourne l’application, il faut assurer un traffic minimal sur l’app pour empêcher cette éventualité.
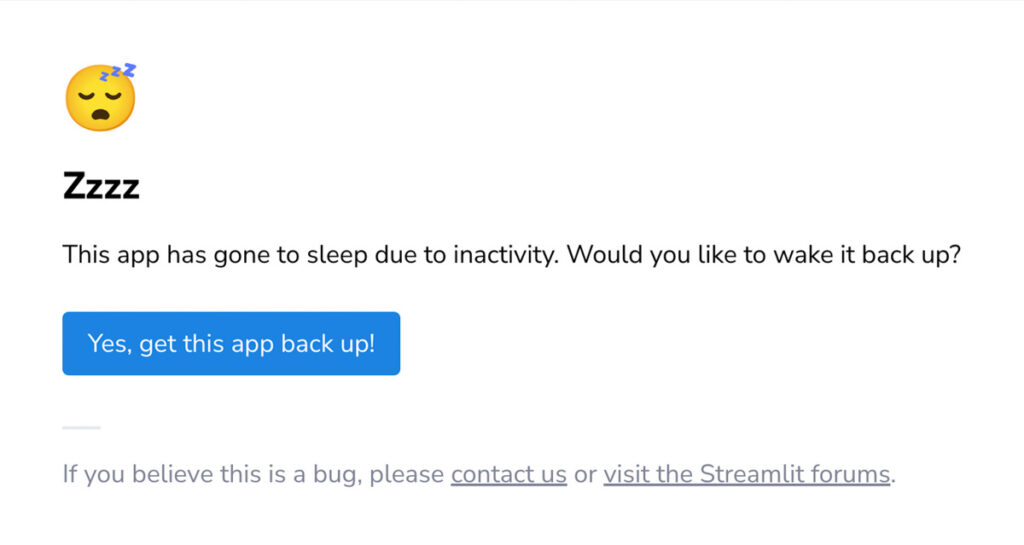
Afin d’être au dessus du seuil minimal d’une visite toutes les 48H (seuil actuel défini par Streamlit), j’ai emprunté et modifié une Github Action d’une autre application très très cool, développée par Jean Milpied2 un Data Scientist Français également !
Voici le fichier YAML Github Action :
name: Trigger Probe of Deployed App on a CRON Schedule
on:
schedule:
- cron: "0 */48 * * *"
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
jobs:
build-and-probe:
runs-on: ubuntu-latest
steps:
- name: Checkout Repository
uses: actions/checkout@v2
- name: Build Docker Image
run: docker build -t my-probe-image -f probe-action/Dockerfile .
- name: Run Docker Container
run: docker run --rm my-probe-imageL’action qui va sonder si l’application est off ou non est un script JavaScript, exécuté par Puppeteer :
const puppeteer = require("puppeteer");
const TARGET_URL = "
const WAKE_UP_BUTTON_TEXT = "app back up";
const PAGE_LOAD_GRACE_PERIOD_MS = 8000;
console.log(process.version);
(async () => {
const browser = await puppeteer.launch({
headless: true,
ignoreHTTPSErrors: true,
args: ["--no-sandbox"],
});
const page = await browser.newPage();
console.log(page); // Print the page object to inspect its properties
await page.goto(TARGET_URL);
console.log(page); // Print the page object to inspect its properties
// Wait a grace period for the application to load
await page.waitForTimeout(PAGE_LOAD_GRACE_PERIOD_MS);
const checkForHibernation = async (target) => {
// Look for any buttons containing the target text of the reboot button
const [button] = await target.$x(
`//button[contains(., '${WAKE_UP_BUTTON_TEXT}')]`,
);
if (button) {
console.log("App hibernating. Attempting to wake up!");
await button.click();
}
};
await checkForHibernation(page);
const frames = await page.frames();
for (const frame of frames) {
await checkForHibernation(frame);
}
await browser.close();
})();Le déclenchement est effectué via une image Docker de Puppeteer :
# probe-action/Dockerfile
FROM ghcr.io/puppeteer/puppeteer:17.0.0
COPY ./probe-action/probe.js /home/pptruser/src/probe.js
ENTRYPOINT [ "/bin/bash", "-c", "node -e \"$(</home/pptruser/src/probe.js)\"" ]Avec cette technique, toutes les 48 heures, le script va venir sonder l’application à l’URL fournie (la page d’accueil) et donc s’assurer que l’app est up (sinon il va cliquer sur le boutton Wake Up)
Actuellement, le seul élément qui manque à la version actuelle serait la possibilité de faire des déploiement en Green/Blue (avec une base tampon qui charge les anciennes données, pendant que la base couramment utilisée après le refresh n’est pas trop sollicitée par un hard refresh). En effet, vous l’aurez compris, actuellement si l’application crashe ou bien si le serveur est décommissionné (ce qui est probable, j’image que Streamlit doit mettre les app sur des SpotInstances pour ne pas faire exploser la facture ). J’ai déjà expérimenté plusieurs reboot de l’app depuis son déploiement en phase beta, donc c’est un risque.
En effet, on perd la DB, mais instaurer un système Green/Blue va bien au delà de la stack technique actuelle, c’est un peu overkill pour le projet. Je me note seulement pour le futur de faire un petit script de restauration sauvegarde et de restauration de la DB depuis son dernier bootstrap pour le futur. Avec le S3 cela ne devrait pas être bien sorcier, et surtout que nous ne souhaitons garder que les CustomStation et les Followed GasTypes.
Conclusion
Streamlit est un outil extrêmement polyvalent, qui donne la possibilité de :
- Crafter une petite application, avec une UI rapidement sympa, et à peu près responsive, et déjà en soi c’est dingue.
- Avec quelques hacks, on peut construire un ETL basique pour rafraîchir automatiquement la donnée qui est exposée. A ne pas considérer comme un système de PROD, c’est un peu cracra, mais ça marche et ça tourne à peu près. Pour un petit projet fun, c’est amplement suffisant.
Dans tout projet Data, assurez-vous d’avoir un schéma de donnée cohérent et évolutif. Construire ensuite votre front et la logique de l’application n’en sera que diablement plus simple et efficace.
En plus d’avoir des objets d’ORM élégants.
Un grand merci aux différents développeurs qui ont open-sourcé leurs apps(pdf-workdesk, reparatorAI, librairies (Streamlit-Authenticator), sans eux le travail aurait été plus complexe, voire disons-le impossible. Allez leur mettre des 🌟, ça leur fera le plus grand plaisir !
Merci également aux équipes de Streamlit pour la possibilité de déployer gratuitement nos dashboards.
Cette note de blog a initialement été publiée sur mon blog et c’est avec plaisir qu’elle a été rééditée afin d’être proposée aux lecteurs du blog ReBirth, j’espère que cela vous a intéressé !
- Une app développée par Siddhant Sadangi, un streamlit Granmaster. Allez jeter un oeil à ses autres applications sur Github, elles sont trop cools ! ↩︎
- Une autre app sympa, donnant des informations à la sauce BI avec les probabilités de réparer son appareil domestique. L’app a récemment eu raison sur ma dernière machine à espresso manuelle 😃 Jetez un oeil ici pour le déclenchement de l’app, et vous pourrez creuser le blog originel de l’idée ici initialement crée par David Young. ↩︎