
Prompt Engineering, RAG, Fine Tuning ou Prompt tuning : quelle méthode choisir ?
Temps de lecture : 9 minutes
Si vous avez entendu parler de près ou de loin des LLM (Large Language Model), vous avez certainement déjà été confronté aux mots clefs suivants : “Prompt Engineering”, “Prompt Tuning, “RAG”, “Fine tuning”. De quoi s’agit-il ? Ces différentes méthodes permettent d’adapter un LLM à des tâches spécifiques.
Chez Devoteam, nous luttons contre les raccourcis intellectuels, et au-delà du jargon purement technique, ces techniques concernent des utilisations et des cas d’usage bien différents. Et c’est pour cela que nous avons choisi de les détailler pour vous dans cet article.
Prompt Engineering
Le prompt Engineering, c’est l’art de rédiger un bon prompt. Il est la première brique essentielle si vous souhaitez tirer parti des LLMs. Sa définition est simple : travailler le corpus que vous envoyez au LLM pour que l’inférence récupérée soit le plus proche possible de vos attentes. Parmi ces techniques, nous pouvons retrouver “Few-Shot”, “Chain of thought” qui consistent respectivement à donner des exemples d’output attendu au modèle et expliquer le raisonnement réalisé afin que celui-ci soit reproduit.
Le prompt Engineering est souvent utilisé en premier lieu, car il ne nécessite ni connaissances, ni puissance de calcul supplémentaire.
Et si vous souhaitez devenir des maîtres en la matière et améliorer la pertinence des réponses de vos LLM, des frameworks existent ! Comme celui de Prompt Engineering Guide par exemple, mais, nous vous conseillons en premier lieu de lire les guides sur les prompts d’OpenAI pour GPT, de Facebook pour Llama ou encore de Anthtopic pour Claude pour directement comprendre les subtilités de leurs “models card”.
L’image 1 ci-dessous, présente les cinq piliers pour faire un bon prompt d’après OpenAI.
Image 1 : Exemple des stratégies de Prompt Engineering (Taylor, 2023).
Retrieval Augmented Generation
Nous vous avions parlé du RAG (Retrieval Augmented Generation) dans notre revue de presse avec l’article Question answering using Retrieval Augmented Generation – RAG – with foundation models in Amazon SageMaker JumpStart.
Le RAG est une approche “context-based” permettant d’ajouter dans le prompt, en plus de la question initiale, des informations de réponses probables contenues dans une source experte.
Il existe différentes stratégies de RAG. La version la plus simple consiste à comparer l’embedding (représentation du texte sous forme vectoriel, comme l’illustre l’image 2) du prompt initial avec ceux d’une “Knowledge vector Database” (image 3). Les éléments les plus similaires au prompt initial seront ainsi ajoutés comme élément de contexte au prompt envoyé au LLM.
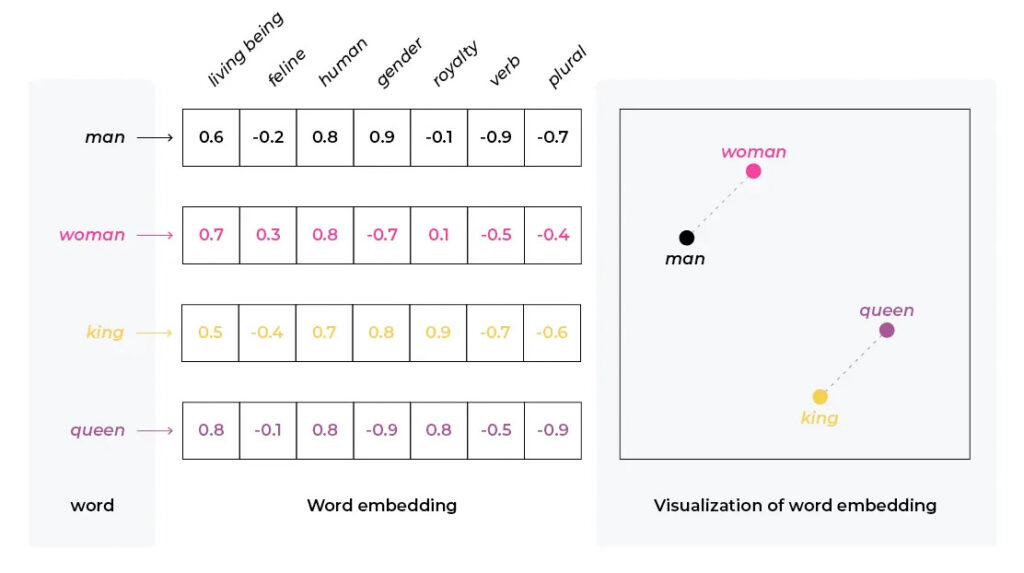
Image 2 : Exemple d’embedding des mots avec la représentation visuelle des distances (Castillo, 2023).
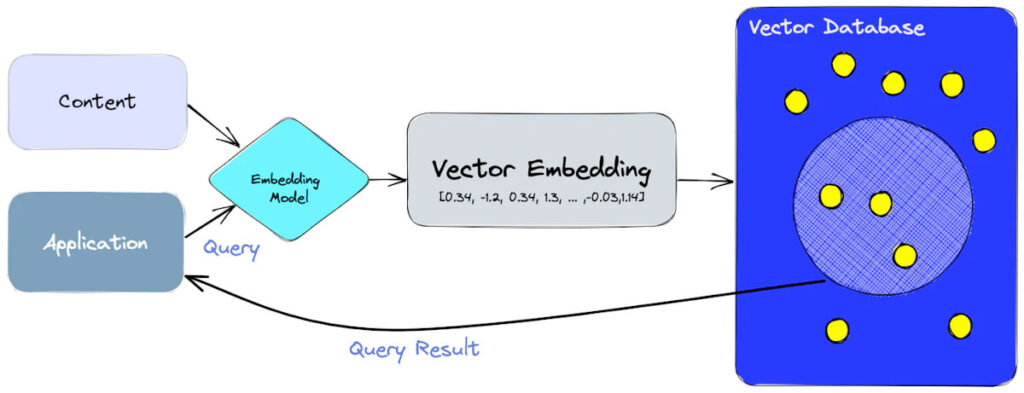
Image 3 : Exemple de la chaine : contexte → modèle d’embedding → Vector DB (Schwaber-Cohen, 2023).
Ainsi, disposant “théoriquement” de la connaissance nécessaire, le LLM n’aura plus qu’à reformuler la réponse pour qu’elle soit davantage “user friendly”. Les versions plus avancées sont composées de phase de “rewrite” de la question initiale permettant d’avoir de meilleures performances dans le retriever.
Mais, ce qui va impacter le plus la performance est avant tout l’algorithme d’embedding utilisé. Pour cela, vous aurez l’embarras du choix: “Ada-002” de OpenIA, “Gecko” de Google (Vertex IA), “Titan Embedding” de chez AWS (Amazon Bedrock)… Les tendances évoluent tellement vite que la liste précédente sera très certainement devenue obsolète quand vous lirez ces mots. Ainsi, le choix ne doit pas être porté par la mode, il doit être le fruit d’une mûre réflexion. En effet, une fois tous nos documents choisis et ingérés dans notre vecteur database, il sera coûteux de recommencer l’opération si on veut changer de modèle d’embedding.
D’autant plus qu’à l’instar du modèle propriétaire des consoles de jeux, il n’est pas possible d’utiliser un embedding A sur des documents vectorisés par le modèle B. Pour cela, nous basons nos études comparatives sur au moins trois critères :
- la pertinence du modèle (embedding audio, image, texte, …)
- la performance de l’api (temps de réponse)
- le prix
Cette technique nécessite donc un minimum de connaissances. Sa mise en place sera ainsi plus longue et coûteuse. Car en plus de s’assurer que les données à disposition sont “propres” et exploitables, il faut également mettre en place plusieurs briques technologiques supplémentaires : a minima, une base données vectorielle, un pipeline d’ingestion et un “retriever” pour que les documents stockés soient utilisables par le système.
Pour approfondir le sujet, nous vous conseillons cet article sur les points bloquants que l’on peut rencontrer durant un projet RAG : 12 RAG Pain Points and Proposed Solutions.
Par ailleurs, si vous souhaitez utiliser la même architecture pour l’ensemble des RAG développés dans votre entreprise, vous allez certainement devoir intégrer à vos réflexions la gouvernance des données pour intégrer leur cycle de vie et pour pouvoir restreindre l’accès à certaines informations. Cela vous permettra de ne développer qu’une seule architecture pour tous les cas d’usage.
De nos jours, nous pouvons observer une augmentation sans fin du nombre de tokens qu’on peut fournir à notre LLM. Un token est l’unité de mesure du découpage de notre prompt, et il varie en fonction de la langue utilisée et du modèle d’embedding utilisé (voir How To Understand, Manage Token-Based Pricing of Generative AI Large Language Models). Nous pouvons ainsi nous demander si le RAG a toujours son intérêt puisque par exemple, dans Claude3 on peut lui fournir l’équivalent de 300 pages dans son contexte.
Si telle est votre décision, attention aux dégradations de performance, car vous risquez de rencontrer le problème de “Lost in the middle”. Pour aller plus loin dans la réflexion, il serait intéressant de comparer le coût complet de l’architecture nécessaire au RAG au prix au token des modèles accessibles en SAS.
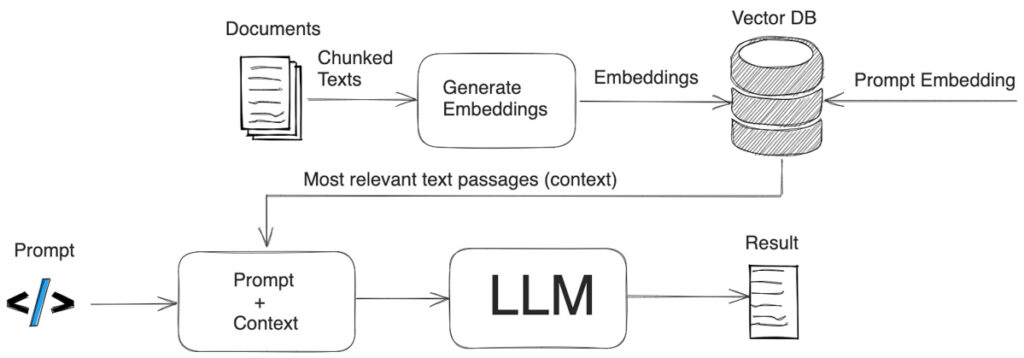
Image 4 : Schéma du framework RAG avec les composent (Safjan, 2023)
Fine Tuning
Le “fine-tuning” d’un modèle consiste à compléter l’apprentissage du modèle avec de nouvelles données (image 5). Cette méthode est intéressante si vous souhaitez faire apprendre aux modèles une façon spécifique de répondre, ou si vous souhaitez qu’il améliore ses connaissances dans un domaine particulier.
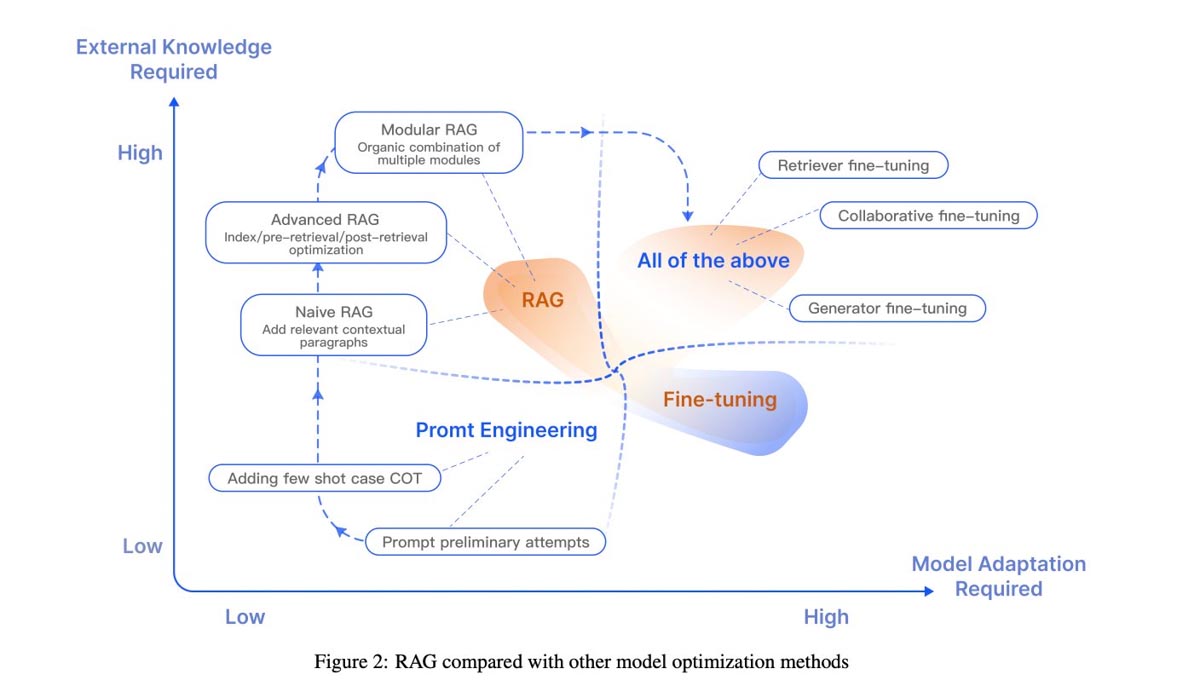
Image 5 : Schéma de la logique derrière le Fine Tuning (Raschka, 2023).
Aujourd’hui, peu d’entreprises ont recours au “fine tuning”, pour deux raisons principales :
- Affiner les modèles nécessite des données de qualité (toujours le même combat finalement…).
- Le fine-tuning nécessite une telle puissance de calcul que cela peut devenir très coûteux pour les entreprises.
Par exemple, dans l’article le Fine-Tuning de Mixtral, on parle de 48h d’entraînement sur une A100. Sur AWS, si on utilise une instance p4d.24xlarge, cela représenterait un coût d’entraînement de 1572.96 €.
Outre l’aspect financier, nous pouvons aussi regarder l’impact environnemental que l’apprentissage de ces modèles génèrent. L’association DataForGood estime dans son livre blanc “Les grands défis de l’IA générative » que l’apprentissage de GPT3 aurait généré 552 tonnes CO2, soit l’équivalent de 200 aller/retour Paris – New York. Or quand nous regardons la taille des “context windows” des nouveaux modèles, nous pouvons penser que leur impact est bien supérieur à celui-ci.
Doit-on pour autant bannir cette méthode pour des raisons écologiques ? Certainement pas, mais on peut se poser la question deux fois, avant de lancer un énième fine-tuning.
Faire du fine-tuning n’est pas toujours sans risque pour la performance du modèle, nous avons déjà observé des cas où les données utilisées pour ce nouvel apprentissage viennent écraser et remplacer toutes les connaissances que pouvait avoir apprises le modèle initialement. On parle alors de “Catastrophic Forgetting”.
Pour s’assurer que ce n’est pas le cas, vous devez implémenter une logique LLMOPS (ML Ops pour les modèles LLM). Premièrement pour “Savoir qu’on ne sait pas” mais aussi pour quantifier cette perte de connaissance. Dans cet article “Analyzing the Forgetting Problem in the Pretrain-Finetuning of Dialogue Response Models“, les dataset CCNEWS, Dailydialog, Switchboard et Cornell Movie ont été utilisés pour mener à bien leurs expériences et ainsi étudier ce phénomène.
L’article RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture, proposé par Microsoft met en avant une approche mixte que nous avons trouvé intéressante à vous partager. En résumé, ils ont utilisé un premier RAG pour construire une knowledge database qu’ils ont ensuite utilisée pour approfondir les connaissances d’un LLAMA 2. Lors de l’inférence, ce nouveau modèle est de nouveau boosté par un autre RAG afin de contextualiser encore plus les questions.
Cette approche semble porter ses fruits, car comme le résume très bien @omarsar0 dans son post : « Accuracy increase of over 6 p.p. when fine-tuning the model and this is cumulative with RAG, which increases accuracy by 5 p.p. further.«
« Demonstrate that the fine-tuned model leverages information from across geographies to answer specific questions, increasing answer similarity from 47% to 72%. »
Prompt Tuning
Il est difficile de parler du prompt tuning sans entrer dans les détails techniques. Pour faire simple, quand on envoie un prompt à un LLM, il y a une étape, transparente pour les utilisateurs, où le texte (en langage humain) se transforme en données interprétables par la machine : un vecteur. On appelle cette étape la tokenisation. L’innovation du prompt tuning est dans l’ajout de “soft” prompt. Et c’est ce soft prompt qui sera modifié lors de l’entraînement du LLM.
L’avantage principal du prompt tuning est qu’on conserve l’intégrité du modèle et l’apprentissage réalisé n’altéra pas ses connaissances. De plus, les coûts de prompt-tuning sont moins importants que ceux engendrés pour du fine-tuning. Pour en comprendre davantage et tester par vous-même, nous vous conseillons la lecture de cet article Understanding Prompt Tuning: Enhance Your Language Models with Precision qui contient un tuto d’utilisation de la librairie PEFT (Parameter-Efficient Fine-Tuning).
Conclusion
Le choix de la méthode à utiliser est donc une question de cas d’usage et de maturité. Pour illustrer nos propos et synthétiser les différentes méthodes, nous vous vous proposons de terminer par cette illustration :
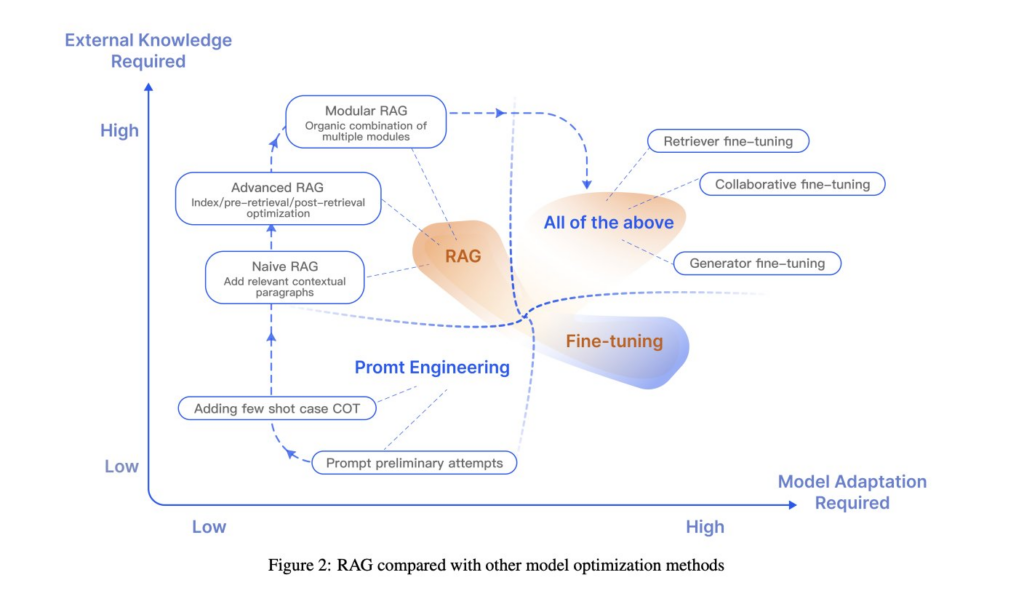
Image 6 : RAG compared with other model optimization methods (Gao et al, 2024)
- Castillo, F., 2023 : Embeddings: Meaning, Examples and How To Compute
- Raschka, S., 2023 : Finetuning Falcon LLMs More Efficiently With LoRA and Adapters
- Safjan, K., 2023 : Understanding Retrieval-Augmented Generation (RAG) empowering LLMs
- Schwaber-Cohen, R., 2023 : What is a Vector Database & How Does it Work? Use Cases + Examples
- Taylor, M. 2023 : Prompt Engineering: From Words to Art and Copy.
- Gao et al., 2024 : Retrieval-Augmented Generation for Large Language Models: A Survey